
← Back To Blog
Learning from Feedback: Automate Upwork Bidding in 2026

You open Upwork in the morning to “just check new jobs,” and an hour disappears. You scroll past vague briefs, low-budget posts, recycled listings, and clients who were never a fit in the first place. Then you send a few proposals, wait, refresh, second-guess your wording, and repeat the cycle tomorrow.
That routine doesn't break because you work harder. It breaks when you treat bidding like a feedback system instead of a manual hustle.
For freelancers and agencies, learning from feedback usually gets framed as a soft skill. Useful, but vague. In practice, it's a hard operational process. You define what a good lead looks like, reject what wastes time, tighten proposal language, and keep feeding those decisions back into the system until the machine starts making better choices on your behalf.
That's the core shift in automated Upwork bidding. You're not just turning on software. You're teaching a system how to spot your ideal jobs, how to ignore the noise, and how to respond in a way that sounds like your business. The quality of that automation depends on the quality of your feedback.
From Endless Scrolling to Automated Success
Most Upwork burnout starts before the proposal. It starts in filtering.
A strong freelancer might only want projects in one stack, one budget range, one client maturity level, and one type of engagement. A strong agency is usually even narrower. Maybe you want long-term web app builds, not quick bug fixes. Maybe you want B2B SaaS clients, not ecommerce stores. Maybe your team closes best when the client has a clear brief and realistic expectations. But Upwork doesn't hand you that clean pipeline by default.
So people compensate with labor. They read everything. They over-monitor the feed. They manually rewrite proposals. They react instead of operating from a system.
Why manual bidding stalls good businesses
Manual bidding can work when volume is low and your standards are loose. It breaks when either of those changes.
The moment you need consistency, a manual process creates three problems:
- You review too much noise. Bad-fit jobs consume the same attention as high-fit jobs.
- Your standards drift. What looked like a bad lead on Monday starts looking “good enough” on Friday.
- You lose response speed. Good clients often reward the first strong response, not the fifteenth.
For agencies, the cost is even heavier. One bidder likes startup clients. Another prefers enterprise retainers. A founder wants to avoid fixed-price work, but the operator keeps chasing it. Without a shared loop, everyone “uses judgment,” and the system never improves.
Feedback turns preference into process
Learning from feedback becomes practical in this context.
Every approval teaches the system what to pursue again. Every rejection teaches it what to suppress. Every edit to a proposal teaches it how your positioning should sound in a real selling context. Over time, feedback stops being commentary and starts becoming training data for your workflow.
The fastest way to improve bidding quality isn't writing more proposals. It's reducing how often the wrong jobs ever reach the proposal stage.
That changes the operating model. Instead of asking, “How many jobs can I apply to today?” you start asking better questions:
- What patterns define my best opportunities?
- What signals usually predict wasted effort?
- What proposal language consistently reflects my offer well?
- What should the system do automatically, and what still needs human judgment?
When you answer those questions with repeated feedback, automation gets sharper. The goal isn't blind volume. The goal is a narrower, cleaner stream of opportunities that fit your service, pricing, and close process.
The Foundation of Effective Feedback
Bad feedback feels expressive. Good feedback is operational.
That distinction matters because many individuals think they're teaching a system when they're only reacting emotionally to outputs. “These leads are bad.” “This proposal feels off.” “I don't like what it sent.” None of that is useful unless it points to a pattern the system can act on next time.
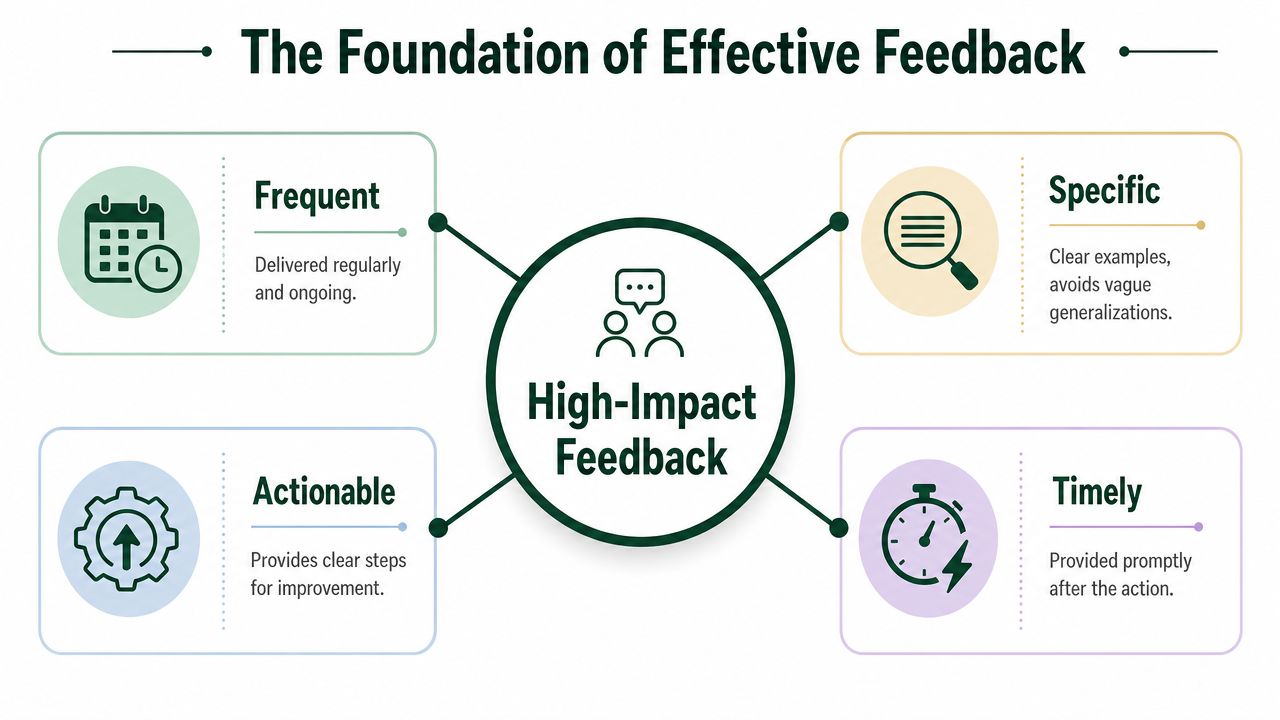
Frequent beats occasional
Feedback works best when it's close to the decision.
A Gallup workplace study found that 80% of employees who said they received meaningful feedback in the past week were fully engaged. The same research found employees were 3.6 times more likely to strongly agree they were motivated to do outstanding work when their manager provided daily rather than annual feedback. Gallup's practical takeaway is simple. Feedback is most effective when it is frequent, focused, and future-oriented.
That principle applies cleanly to automated bidding. If you wait a week to review job matches or proposal behavior, your corrections arrive late. The system has already repeated weak choices. Shorter loops create cleaner learning.
Specific beats vague
“Don't show me bad jobs” is not feedback. It's frustration.
“Exclude clients with thin briefs, unclear deliverables, or obvious mismatches with our core offer” is closer. Better still is feedback tied to observable traits such as job type, budget framing, client history, urgency, skill stack, or engagement model.
Useful feedback usually answers one of these:
- What was wrong with the match
- Which signal should have mattered more
- What should happen next time
- Whether this is a one-off exception or a repeatable rule
If you're training any bidding workflow, specificity does two things at once. It improves job selection, and it improves proposal context. A system can't write a relevant opening if you haven't taught it which contexts matter.
For a deeper look at how sharper input improves Upwork outcomes, see feedback for client communication on Upwork.
Future-focused beats backward-looking
A common mistake is turning feedback into blame. People do it with humans, and they do it with software.
The stronger method is to identify what happened, then move immediately to what should happen next. In a controlled study on feedback acceptance, managers were more likely to accept feedback and intend to change when the conversation emphasized future actions rather than past performance. The reported increase in intention to change was 2.30 to 3.24 points on a 1–7 scale, and future focus was the best predictor of both feedback acceptance and intention to change.
Practical rule: Don't say “this was a bad proposal.” Say “next time, lead with our Shopify migration work when the client mentions replatforming.”
That format is easier to apply, easier to repeat, and easier to scale across a team.
Timely and actionable beat comprehensive
Long feedback audits feel productive, but they usually hide the actual fix.
The highest-value feedback is prompt and tied to an action. If a job should have been rejected, define why. If a proposal intro was weak, rewrite the first sentence pattern. If the system keeps surfacing jobs outside your floor pricing, set a clearer threshold. Actionability matters more than volume.
A reliable feedback note is short enough to implement immediately. That's how learning from feedback stops being abstract and starts shaping the machine.
Training Your AI Bidding Assistant
The simplest training input is usually the most important one. A thumbs-up or thumbs-down looks trivial, but in practice it's the cleanest signal you can send.
When you rate job matches consistently, you stop using the platform like a feed reader and start using it like a trainer. Each click tells the system whether it correctly understood your market, your offer, and your standards.
What a thumbs-up should really mean
Many users approve jobs that are merely acceptable. That slows learning.
A thumbs-up should mean, “If this kind of project showed up more often, I'd want more of it.” That usually includes a combination of service fit, client seriousness, budget alignment, and the kind of work your team can sell confidently.
A few examples make the standard clearer:
- Web development freelancer: Upvote a React dashboard rebuild for a funded fintech company with a clear scope and an experienced client.
- Performance marketer: Upvote a retention-focused email or lifecycle engagement project where the client describes metrics, current tools, and decision-maker access.
- Design agency: Upvote a brand refresh with a defined timeline, stakeholder clarity, and work samples that suggest the client values quality.
The point isn't broad approval. It's pattern reinforcement.
What a thumbs-down should communicate
Downvotes work best when they reject a category, not just a mood.
For instance, a full-stack agency might reject a small PHP maintenance task because it's outside the preferred engagement model. A content strategist might reject jobs asking for “10 SEO blogs by tomorrow” because the client is signaling speed and volume over quality. A paid media specialist might reject clients who want platform setup but have no creative assets, no landing page control, and no clarity on goals.
That's better than random filtering because it creates a profile of non-fit.
Use a thumbs-down when the issue is structural:
- Wrong service type
- Budget mismatch
- Weak client signal
- Bad engagement model
- Poorly defined brief
- Industry or niche you don't want
Don't use it for rare edge cases that you'd still take under the right conditions. Those are exceptions, not training rules.
Train for the next decision
Here, most users either get fast improvement or stay stuck.
The best feedback doesn't just label the current job. It improves the next one. If a project was almost right, note what was missing. If it was right but the proposal angle was wrong, adjust the angle, not the targeting logic.
Here's a useful internal question after every rating: “What should the system do more often after seeing this?”
That keeps your feedback future-focused instead of evaluative. It also mirrors what works in the research on behavior change discussed earlier.
A quick walkthrough helps if you want to see the mechanics in action:
Don't train with mixed signals
The fastest way to confuse any AI bidding assistant is inconsistent judgment.
If you upvote premium strategy projects one day and low-clarity small jobs the next because the pipeline feels slow, you aren't giving market intelligence. You're giving panic data. The system can't learn a stable ideal client profile if you keep changing the definition under pressure.
Good training data comes from disciplined standards, not from whatever feels urgent this afternoon.
If you need to widen your pipeline, do it intentionally. Broaden one variable at a time, such as niche, contract type, or budget floor. Then review whether the new matches support your business model.
Building Your Automation Playbook with Rules and Templates
Thumbs are a starting point. Rules and templates are where the process becomes durable.
Once you've seen the same approval and rejection pattern enough times, the next move isn't more clicking. It's codifying the decision so the system can handle it predictably. That's the difference between reacting to jobs and building an automation playbook.
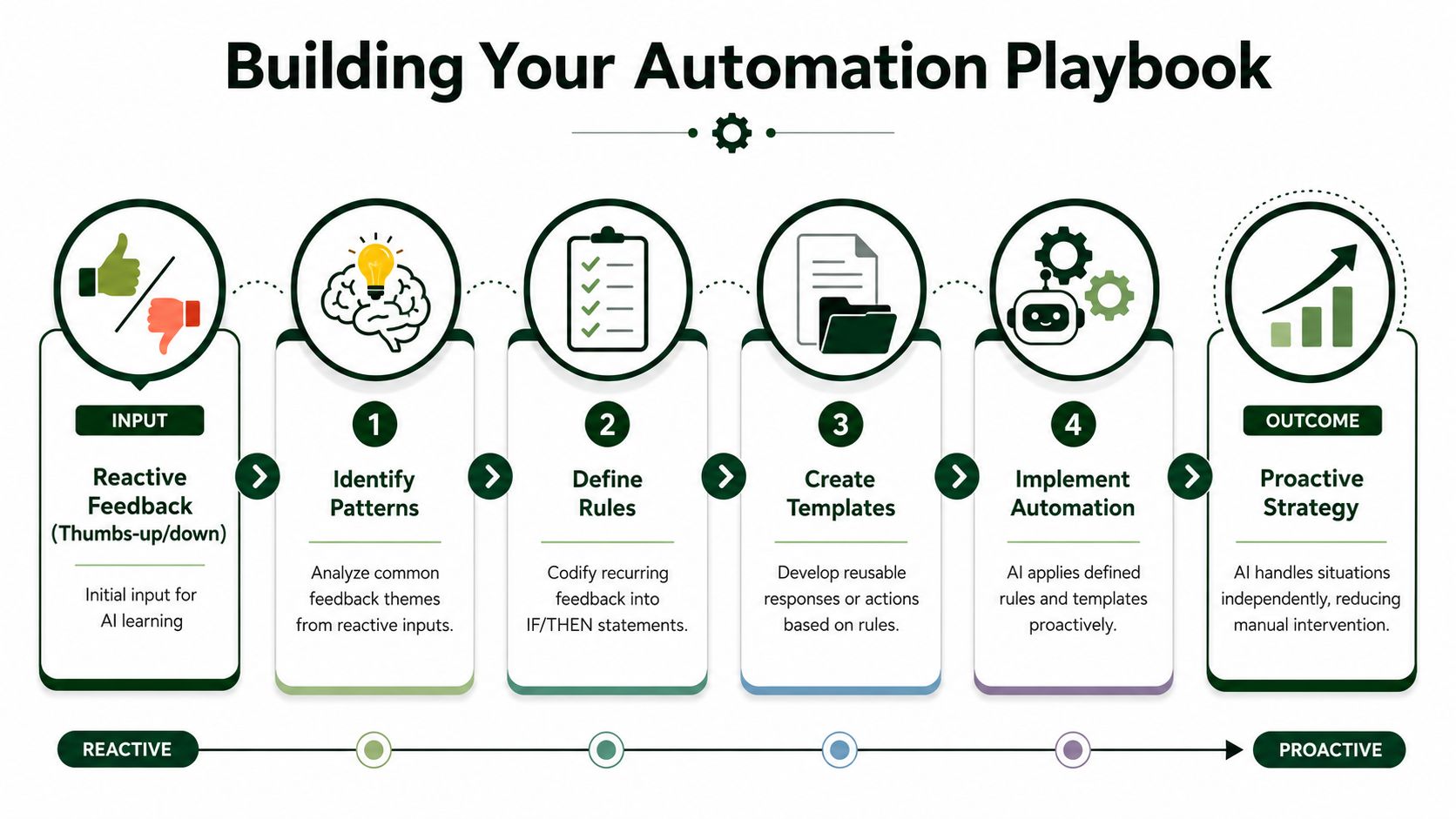
Turn repeated feedback into rules
If you keep rejecting the same category of jobs, that's not a review habit. It's a policy waiting to be written.
A useful rule often takes an if-then shape:
- If the client description is too vague, then don't bid automatically.
- If the project falls outside your core service line, then exclude it.
- If the job mentions a tool, platform, or deliverable you consistently win, then prioritize it.
- If the client asks for unrealistic turnaround without context, then suppress it.
These rules matter because they prevent recurring waste. They also free feedback for higher-value refinement instead of repetitive cleanup.
A 2019 mixed-methods study on feedback found that effective feedback depends on learners being active in the process, that no single feedback design works for every learner, and that feedback works better when multiple sources and modes are used. That maps well to bidding operations. Thumbs, rule-setting, proposal edits, and performance review all contribute different kinds of learning.
For a practical extension of this into proposal workflows, see how to automate Upwork proposals.
Build templates that adapt to context
Templates fail when they sound like templates.
A useful proposal template isn't one generic block with a few swapped nouns. It's a flexible structure that changes based on the kind of job, the client's language, and the evidence you want to lead with.
For example, your proposal playbook might include different openings for:
- Migration work when a client is moving platforms or replacing an existing provider
- Growth work when they already have traction and want better conversion or retention
- Rescue work when a previous freelancer failed or the project is behind
- Long-term support when the client needs a stable operating partner instead of a one-off task
That structure keeps the voice relevant while preserving consistency. It also gives your team a way to review why a proposal angle exists.
Separate hard rules from soft preferences
Not every preference deserves automation.
A hard rule should protect time, quality, or strategic fit. A soft preference should influence ranking, not block opportunities outright. This distinction keeps your system from becoming brittle.
Use hard rules for things that repeatedly waste effort. Use soft preferences for signals that help, but aren't absolute.
If a single exception would still be worth a conversation, it probably isn't a hard exclusion rule.
That one principle prevents a lot of over-filtering.
Keep the playbook readable
Agencies often overcomplicate this phase. The result is a playbook nobody can maintain.
A good automation playbook should be readable by a bidder, a founder, and an account lead. If someone can't explain why a rule exists, that rule will create drift later. Write policies in plain language. Group them by targeting, qualification, and messaging. Review them whenever outcomes shift.
That's how learning from feedback becomes institutional knowledge instead of one person's private instinct.
Measuring the Impact of Your Feedback Loop
If you can't tell whether your feedback improved outcomes, you're not running a loop. You're just making edits.
The most useful measurement habit is simple. Track what changed in your inputs, then watch what changed in your outcomes. That sounds obvious, but many teams never do it. They look at proposal volume because it's visible, while ignoring the signals that tell them whether targeting and messaging are getting sharper.
Start with decision-quality metrics
Volume matters less than fit.
If your proposal count rises but replies fall, your system may be expanding into weaker territory. If proposal count drops but interviews improve, the filtering may be doing its job. For most freelancers and agencies, the health of a bidding loop shows up first in quality metrics such as:
- Client reply rate
- Interview request rate
- Win rate
- Time from job post to proposal
- Manual override frequency
- Share of auto-selected jobs you would have chosen yourself
Those metrics answer different questions. Reply rate tells you whether targeting and openers are resonating. Interview rate says more about relevance and trust. Win rate tests whether the whole chain, from filtering to proposal to follow-up, is aligned with your offer.
Watch for lag between feedback and results
Not every adjustment pays off immediately.
A stricter filter can reduce proposal volume before it improves pipeline quality. A revised template might raise replies but not wins if qualification is still loose. That's why you need to interpret metrics in groups, not alone.
In education research summarized by the American Psychological Association on classroom data and feedback, effective feedback is most powerful when teachers use evidence from lessons to make prompt instructional adjustments, because “the shorter the amount of time between assessment and adjustment the more powerful its effect on learning.” The business equivalent is direct. Review the data soon enough that you can still connect a result to the change that caused it.
Use before-and-after comparisons carefully
You don't need complex attribution to improve bidding. You do need discipline.
A practical review cycle looks like this:
- Change one meaningful variable. Tighten a budget rule, revise a proposal opener, or suppress a weak client category.
- Hold the rest steady long enough to observe the pattern.
- Review outcome quality, not just output quantity.
- Decide whether to keep, reverse, or refine the change.
This avoids a common trap. Teams often change targeting, templates, follow-up language, and review habits all at once, then they can't tell what worked.
Better feedback loops come from cleaner experiments, not from bigger dashboards.
Diagnose the real issue
A drop in replies doesn't always mean the proposal is weak. A rise in interviews doesn't always mean targeting is perfect. Read the metrics like clues.
If proposal volume is healthy but replies are flat, the opening angle may be generic. If replies are good but interviews stall, qualification or positioning may be off. If wins are inconsistent across bidders, the issue may be team calibration rather than market quality.
The best operators treat analytics as a coaching layer. Numbers don't replace judgment, but they do stop you from relying on hunches.
Advanced Workflows and Troubleshooting
When users say, “The AI keeps sending proposals for jobs I don't want,” the first instinct is to blame the system. Sometimes the system does need adjustment. More often, the underlying problem is feedback design.
Bad automation usually reflects one of four issues. The target profile is too vague. The rules are too loose. The feedback is inconsistent. Or the team is mixing preferences from multiple people without a shared standard.
Troubleshoot the input before the output
Start with the pattern, not the incident.
If one bad-fit job slips through, that's normal. If the same type of bad-fit job keeps appearing, ask which instruction allowed it. Did you reject those jobs consistently? Did anyone on the team approve similar ones? Is there a hidden exception in the logic because someone wanted more volume last week?
A simple troubleshooting pass often fixes more than another round of manual review:
- Check consistency: Are similar jobs getting similar ratings?
- Check scope: Is your ideal project definition too broad to be useful?
- Check exclusions: Have repeated non-fit patterns been turned into rules?
- Check messaging: Are templates aligned to the jobs you want?
- Check ownership: Does one person have final say on standards?
That last point matters for agencies. Shared automation without shared judgment creates noise fast.
Don't overload the system with advice
There's a temptation to solve weak outcomes by adding more instructions. That often backfires.
Research and practitioner guidance note that too much advice can reduce autonomy and that learners often need prompts to self-advise. ASCD's guidance on effective feedback explicitly recommends shifting from giving more advice to asking learners how they would improve. That principle is useful in AI operations too. Before adding new rules, ask what the current pattern is already telling you.
Sometimes the right move isn't another rule. It's removing a conflicting one.
When automation gets noisy, add less before you add more.
Agency workflows need calibration, not just access
For a solo freelancer, feedback is mostly a habit problem. For agencies, it becomes a management problem.
A team lead has to decide who defines the ideal job, who can edit templates, who approves new exclusions, and how bidder performance gets reviewed. Without that governance, every bidder trains the system in a slightly different direction.
A workable agency setup usually includes:
- One shared qualification standard for what counts as a strong opportunity
- A controlled proposal library with approved openings and proof points
- Regular review of exceptions so edge cases don't inadvertently become policy
- Team-level analytics review to spot drift across bidders or accounts
If you're building that operating layer, Upwork lead automation for agencies and multi-user workflows is the right direction to study.
Use prompts that force clearer thinking
One of the best ways to improve feedback quality is to stop asking, “Do you like this?” and start asking narrower questions.
Try prompts like:
- Would we want five more jobs like this next week?
- What exact signal made this a fit or non-fit?
- Is this a rule, a preference, or an exception?
- Which proof point should lead the proposal for this job type?
- Did the system misunderstand the client, or did we fail to define the standard?
Those prompts reduce emotional reactions and improve consistency. They also make onboarding new bidders easier because they expose the logic behind decisions.
Learning from feedback becomes powerful when it stops being personal taste and starts becoming a repeatable operating system. That's when automated bidding stops feeling unpredictable and starts behaving like a trained sales function.
If you're ready to turn Upwork bidding into a system instead of a daily scramble, Earlybird AI helps freelancers and agencies train automation through simple feedback, rule-based targeting, proposal personalization, and team workflows that stay aligned as you scale.



